#
KI-Konfiguration
#
Prompt
Das Verhalten und die Antwortqualität Ihres Chatbots können Sie beeinflussen, indem Sie die KI-Interaktion konfigurieren. Die Angaben, die Sie dort hinterlegen, werden für den Prompt für das LLM genutzt.
Prompts sind Anweisungen, die dem KI-Modell gegeben werden, um eine Antwort, eine bestimmte Aktion oder eine Verhaltensweise zu erzeugen. Ein gut formulierter Prompt hilft dem Chatbot, die Absicht des Benutzers besser zu verstehen und relevante Antworten zu liefern.
Tipps für gut formulierte Prompts:
- Seien Sie klar und präzise: Formulieren Sie Ihre Anweisungen so, dass sie leicht verständlich sind und nutzen Sie den Imperativ, z. B. "Bei Fragen nach Stromtarifen, verweise auf den Tariffinder unter www.tariffinder.de". Formulierungen wie "Wenn möglich ..." oder "Es wäre besser, wenn ..." sollten vermieden werden.
- Verwenden Sie einfache Sprache: Vermeiden Sie Fachjargon oder komplizierte Ausdrücke und nutzen Sie einfache, kurze Sätze.
- Vermeiden Sie Mehrdeutigkeiten: Klare Formulierungen helfen, Missverständnisse zu vermeiden.
- Nutzen Sie Beispiele: Geben Sie bei Bedarf Positiv-Beispiele, um Ihre Anweisung zu verdeutlichen (z. B. "Nutzer:innen", wenn die Art zu Gendern definiert werden soll)
- Testen Sie verschiedene Formulierungen: Experimentieren Sie mit verschiedenen Ansätzen, um herauszufinden, welche am besten funktionieren.
Es ist erforderlich, dass Sie die Rolle und die Funktion Ihres Chatbots festlegen. So weiß der Chatbot, welche Rolle er einnehmen soll und welche Funktion (z. B. digitaler Assistent) er erfüllen soll. Bitte beachten Sie, dass alle Angaben unter Umständen wörtlich ausgespielt werden können.
Bitte wählen Sie aus, in welcher Sprache Sie den Prompt verfassen möchten.
Zusätzlich können Sie definieren, wie der Chatbot den*die Nutzer*in führen soll (z. B. Interessen identifizieren und passendes Produkt empfehlen) und Sie können festlegen, in welchem Stil (z. B. formell) der Chatbot kommunizieren soll. Sprache, Kontextbewusstsein und Antwortlänge sind im Basisprompt bereits berücksichtigt.
Der Prompt kann grundsätzlich bei der Verwendung von OpenAIs GPT-Modellen auf Deutsch formuliert werden.
Sollten Sie mit dem deutschsprachigen Prompt nicht den gewünschten Effekt erzielen, kann es sich jedoch lohnen, es mit einem englischsprachigen Prompt zu versuchen. Hintergrund ist, dass bestimmte Sprachmodelle mit einem englischsprachigen Prompt besser funktionieren.
#
Antwortgenerierung
Sie können die Antworten Ihres KI-Assistenten nicht nur durch Prompting, sondern auch durch verschiedene Konfigurationen beeinflussen:
#
Antwortquelle anzeigen
Sie können entscheiden, ob dem*der Endnutzer*in die Quellen, aus der die Antwort generiert wurde, in Form von URLs im Antworttext angezeigt werden sollen. Die URLs werden mit "Hier klicken für weitere Informationen:" eingeleitet und bieten den Nutzer*innen die Möglichkeit, weiterführende oder verwandte Informationen schnell und einfach zu finden.
Für das Ausspielen der Quellen gibt es folgende Konfigurationsmöglichkeiten:
- Similarity-Threshold: Bestimmt, wie ähnlich ein Chunk der generierten Antwort sein muss, um als relevante Quelle angezeigt zu werden. Ein höherer Wert zeigt nur sehr nahe Übereinstimmungen, ein niedrigerer Wert auch weniger genaue Treffer an.
- Aktivierung bzw. Deaktivierung: Wenn aktiviert, werden die relevantesten Quellen als Links zum generierten Antworttext hinzugefügt (nur für RAG-Agenten relevant).
- Maximale Anzahl: Maximale Anzahl von Quellen, die pro Antwort angezeigt werden
#
Auswahl von Anhängen
Wie Sie Anhänge zu Ihren Daten hinzufügen, erfahren Sie hier . Sie können bestimmen, wie viele Anhänge maximal an eine Antwort angehängt werden sollen und festlegen, auf welche Art die auszuspielenden Anhänge ausgewählt werden.
Folgende Optionen stehen zur Verfügung:
- Anhänge aller relevanten Antwortquellen hinzufügen: Die Anhänge aller Quellen, die den Similarity-Threshold überschreiten, werden der Antwort hinzugefügt. Die maximale Anzahl der Quellen kann begrenzt werden.
- Anhänge der besten Antwortquellen hinzufügen: Der gewählte Wert legt einen Bereich fest, in dem Anhänge angezeigt werden, beginnend mit dem Ähnlichkeitswert der am besten übereinstimmenden Quelle (Beispiel: bei einem Wert von 10 und einer Ähnlichkeit des am besten übereinstimmenden Chunks von 0,78 werden Anhänge von Chunks mit einer Ähnlichkeit von 0,68 oder besser ausgewählt)
- LLM eine semantische Entscheidung treffen lassen: Auf Basis der Benennung des Anhangs, des Dateinamens und der generierten Antwort wird eine inhaltliche Entscheidung darüber getroffen, welche Anhänge der Antwort hinzugefügt werden.
#
Informationssuche
Die Antwortqualität wird nicht nur durch die Auswahl eines bestimmten Modells oder die Konfiguration der Antwort bestimmt, sondern auch bereits durch die Informationssuche. Lassen Sie sich hierzu gern von Ihrer Kauz-Projektleitung beraten.
#
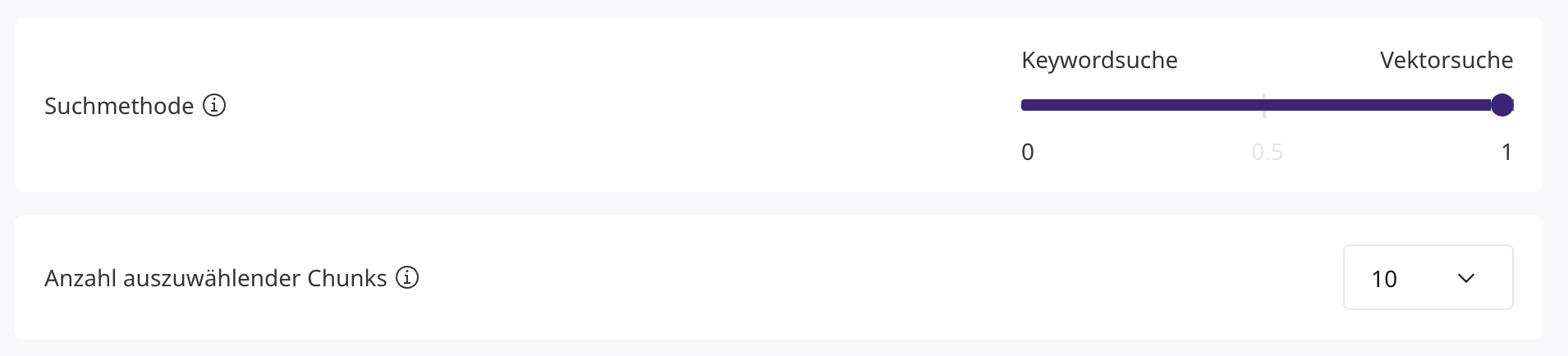
Suchmethode
Bei der Nutzung des RAG-Ansatzes können verschiedene Suchmethoden (Vektorsuche und Keywordsuche) zum Einsatz kommen und kombiniert werden (hybride Suche). Mithilfe des Schiebereglers können Sie bestimmen, wie groß der Anteil welcher Suchmethode sein soll.
Details zu den jeweiligen Suchmethoden und der Auswahl der passenden Methode finden Sie hier .
#
Hohe Keyword-Scores stärker gewichten
Bei der hybriden können Chunks mit hohen Keyword-Scores zusätzlich bevorzugt werden.
Funktionsweise: Wenn die Keywordsuche einen Chunk mit einem besonders guten Score identifiziert, wird der Gesamt-Score dieses Chunks nochmals erhöht. Dadurch werden Treffer mit exakten Keyword-Übereinstimmungen stärker priorisiert, ohne die semantische Komponente vollständig zu verlieren.
Vorteil: Dokumente mit präzisen Keyword-Treffern erscheinen weiter oben in den Ergebnissen, auch wenn die Vektorsuche andere Dokumente als semantisch ähnlicher einstuft.
Anwendungsfall: Besonders nützlich, wenn spezifische Begriffe, Eigennamen, Produktnummern, Gesetzesparagraphen oder Fachterminologie in der Anfrage vorkommen – die Erhöhung des Scores sorgt dafür, dass exakte Übereinstimmungen nicht von semantisch ähnlichen, aber weniger präzisen Treffern verdrängt werden. Aktivieren Sie diese Option nicht, wenn Ihre Datenbasis in verschiedenen Sprachen vorliegt.
#
Längenbasiertes Score-Boosting
Wenn innerhalb eines Agenten lange und kurze Chunks (z. B lange Websitechunks und kurze Chunks aus einer manuellen FAQ-Liste) durchsucht werden, kann das Problem auftreten, dass die längeren Chunks höhere Scores erhalten. Lange Chunks enthalten Keywords oft mehrfach (teilweise auch als Stichworte oder Navigationselemente), aber nicht immer im richtigen Kontext. Kurze FAQ-Texte haben Keywords seltener, aber direkt zusammen mit der Antwort.
Dasselbe Problem tritt auch bei der Vektorsuche auf: Große Chunks enthalten typischerweise mehr semantisch ähnliche Wörter zum Suchkontext, wodurch sie einen höheren Vektor-Ähnlichkeits-Score erhalten – unabhängig davon, ob sie die gesuchte Information tatsächlich enthalten. Wenn ein Chunk beispielsweise viele Wörter wie "Bibliothek", "lernen" oder "lesen" enthält und ein Nutzer nach "Kann ich ein Buch ausleihen?" fragt, wird dieser Chunk möglicherweise höher bewertet als ein kürzerer, aber tatsächlich relevanter Chunk, der konkrete Informationen wie "Bücherausleihe jeden Montag bis Freitag zwischen 8 und 14 Uhr" enthält. Der größere Chunk wirkt semantisch ähnlich, bietet aber nicht die gesuchte Antwort.
Bei der Suche werden die längeren Texte deshalb bevorzugt – obwohl die kurzen Antworten oft besser passen würden. Um dies auszugleichen, können lange Chunks bei der Suche weniger gewichtet werden
#
Anzahl auszuwählender Chunks
Wählen Sie aus, wie viele Chunks bzw. extrahierte Abschnitte für die Antwortgenerierung verwendet werden sollen. Generell gilt, dass bei kleinen bzw. kurzen Chunks mehr Chunks für die Antwortgenerierung herangezogen werden sollten. Bei sehr großen Chunks müssen weniger Chunks für die Antwortgenerierung herangezogen werden.